推薦システム(レコメンド)を学び直したので基礎をまとめる

推薦システム(レコメンド)とは「複数の候補から価値あるものを選び出し、意思決定を支援するシステム」です。この度、とあるプロジェクトで推薦システム、いわゆるレコメンド機能を構築・実装することになりそうでして、あらためて「推薦システムとはなんぞや?」を学びなおしました。その際に『推薦システム実践入門』という書籍が非常によくまとまっていたのでポイントをまとめます。開発エンジニアやプロダクトマネージャーにとってレコメンドシステムの技術や基本的な仕組みの入門になれば幸いです。
後になって知りましたが、推薦システム界隈で話題の技術書だったようですね。他にも何冊かこの類の本は読んだことがあるのですが、どれも数式が多かったり技術的な説明に終始していたり、内容が古かったりで読みづらかったので、割と最近のインターネットサービスの事例も含めて分かりやすく解説している本書は非常に価値がある一冊だと思いました。もっと前からこういう本があれば遠回りしなくて済んだのにな〜と思う良書です。こういう技術書が増えると良いなと思います。
▼電子書籍(Kindle)の読み放題はIT・コンピュータ系の技術書が多くおすすめです♪
Kindle Unlimitedで本の読み放題!無料体験する
推薦システムの3要素
推薦システムの中身は3要素に分解して考えるとわかりやすいです。「インプット(データの入力)」「プロセス(推薦の計算)」「アウトプット(推薦の掲示)」の3つです。それぞれさらに分割すると以下のように区分できます。
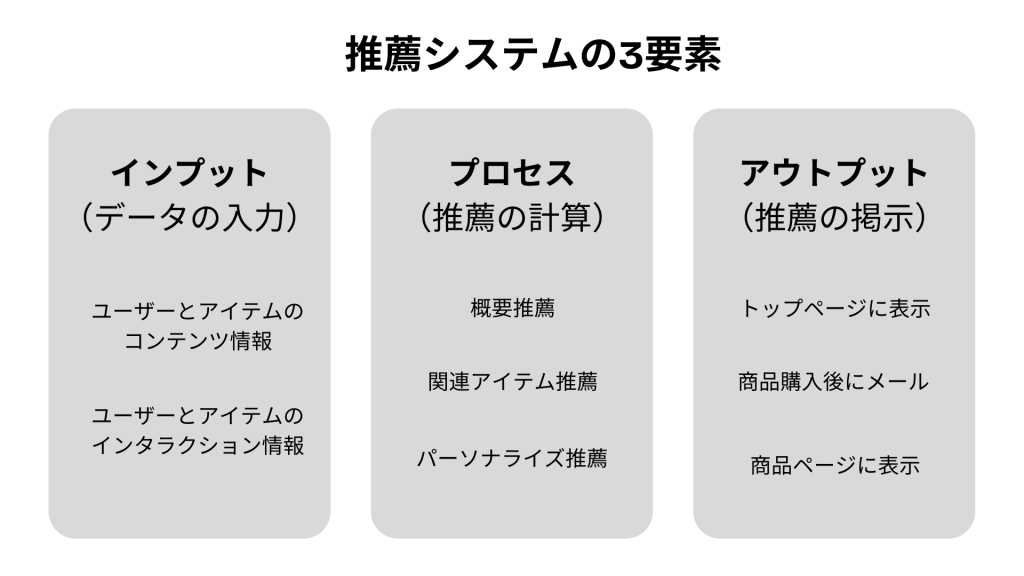
- 1. インプット(データの入力)
- ユーザーとアイテムのコンテンツ情報
- ユーザーとアイテムのインタラクション情報
- 2. プロセス(推薦の計算=パターン、アルゴリズムなど)
- 概要推薦
- 関連アイテム推薦
- パーソナライズ推薦
- 3. アウトプット(推薦の掲示=UI/UXなど)
- トップページに表示
- 商品購入後にメール
- 商品ページに表示
それぞれ解説します。
1. インプット(データの入力)
全ての推薦の元になるデータのインプットです。ユーザーとアイテムのコンテンツ情報と、ユーザーとアイテムのインタラクション情報の2つに分けられます。
ユーザーのコンテンツ情報は年齢、性別、住所、好みのカテゴリ、価格帯などのプロフィール情報や嗜好情報を指します。アイテムのコンテンツ情報はカテゴリ、メーカー、商品説明文、発売日、価格、などを指します。これらコンテンツ情報を利用した推薦をコンテンツベースフィルタリングと言います。
インタラクション情報とはユーザーがそのサービス内で行動した行動履歴のデータです。例えば閲覧、購入、ブックマーク、評価などのアイテムに対するユーザーの行動データを指します。当然ながらユーザーがたくさん行動してくれるとデータが溜まって推薦の精度も高まっていきます。これらインタラクション情報を利用した推薦を協調フィルタリングと言います。
尚、サービス利用初期のユーザーや、新商品に対する行動データは蓄積されづらく推薦されづらく、協調フィルタリングでの推薦は難しいです。これはコールドスタート問題と呼ばれています。そのような新規ユーザーや新規アイテムの推薦はコンテンツベースフィルタリングを用いて行うことが多いです。
2. プロセス(レコメンドの計算=パターン、アルゴリズムなど)
インプットデータの活用方法としては主に3つのパターンがあります。「概要推薦」「関連アイテム推薦」「パーソナライズ推薦」です。

概要推薦はいわゆる「売れ筋ランキング」や「新着順」「人気順」など全ユーザーに同じ内容を掲示する推薦です。最もシンプルに実装できますし、多くのサービスにおいて非常に重要な要素となっています。
下手なレコメンドよりも、これら概要推薦のほうがパフォーマンスが高くなる事例も多いです。実務でもコスパが最も良い機能の1つなのでこういった推薦やユーザー自身でソートできる機能などはまっさきに導入を検討したいですね。
関連アイテム推薦は「このアイテムをチェックした人はこちらもチェックしています」や「この商品に似ている商品」「合わせて買われている商品」など関連するアイテムの推薦です。UIとしては各商品ページの下方に表示されていることが多いです。
各アイテムの類似度を利用して近しい商品をおすすめします。アイテムのコンテンツ情報を活用してコンテンツベースフィルタリングというアルゴリズムで推薦したり、ユーザーの行動履歴を元にして一緒にチェックされている商品を計算して推薦する協調フィルタリングというアルゴリズムがあります。
近しいといっても比較検討を一緒にされやすいかどうか、購入を一緒にされやすいかどうか、で推薦するアイテムが全然変わってきます。プリンターとインクの例がわかりやすいです。プリンター同士は比較検討されるけど同時購入はされない。プリンターとインクは購入を一緒にされやすい。なども考慮して設計する必要があります。
パーソナライズ推薦はユーザーの行動履歴や登録情報を元に1人1人に個別化した推薦です。「閲覧履歴」や「あなたにおすすめ」などがあります。こちらもコンテンツベースで推薦することもあれば、協調フィルタリングで推薦することもあります。
コールドスタート問題の対処も兼ねて初期ユーザーにはユーザーが入力した年齢や住所、興味カテゴリなどを元にアイテムを推薦するコンテンツベースフィルタリングを使うことが多いです。
行動履歴が溜まってきたあとは協調フィルタリングの手法を使い予測精度を高めていきます。例えば閲覧履歴などは実装コストが低い割に効果が高い機能の1つです。まだ導入していないプロダクトにはぜひ導入を検討したいです。
アルゴリズムは前述のとおり「コンテンツベースフィルタリング」と「協調フィルタリング」の2つがあります。これらは追って説明していきます。
3. アウトプット(レコメンドのUI/UX)
どれだけたくさんのデータがあり、どれだけ素晴らしいアルゴリズムを用いても、ユーザーが実際に触れるUIやUXが悪ければ宝の持ち腐れです。
アルゴリズムと同じくらい「どのようにユーザーに表現するのか」は大切な要素です。この商品と一緒に購入されている商品、購入履歴を元にしたおすすめ商品、などのように推薦理由を提示することも非常に重要です。
ここではよく使われているレコメンド機能のUIを画像付きで取り上げていきます。
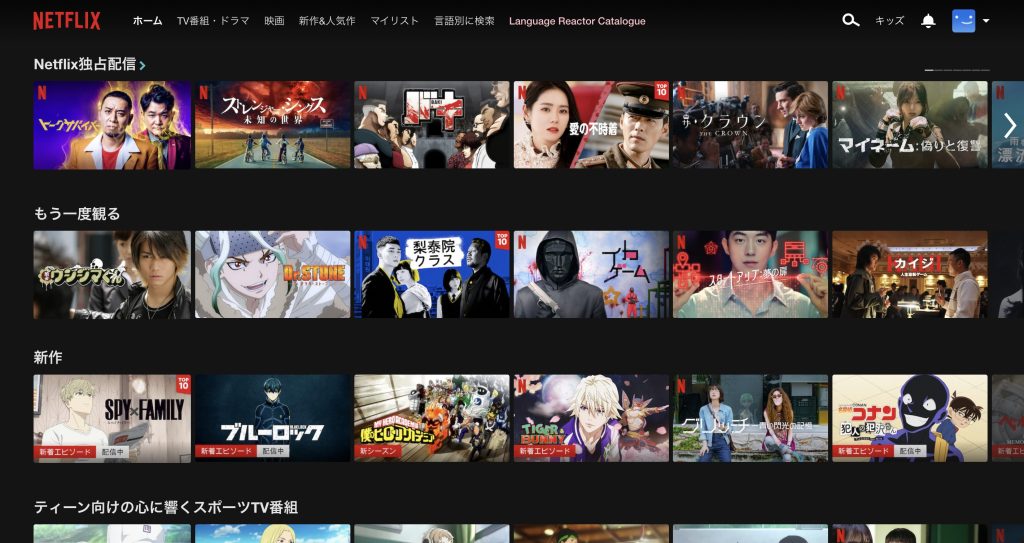
Netflixは複数のレコメンドリストを1つの画面に表示するUIを採用しています。このUIの特徴は概要推薦(Netflix独占配信、新作)、パーソナライズ推薦(もう一度みる、あなたにピッタリの作品)のように複数の推薦アルゴリズムを一画面におさめている点です。ユーザーは画面遷移せずに、そのときの気分に応じて見たい動画を探すことができます。1つのリストでお気に入りが見つからなくても、画面遷移なしで次のリストを閲覧できるのでストレスが少ないUXになります。
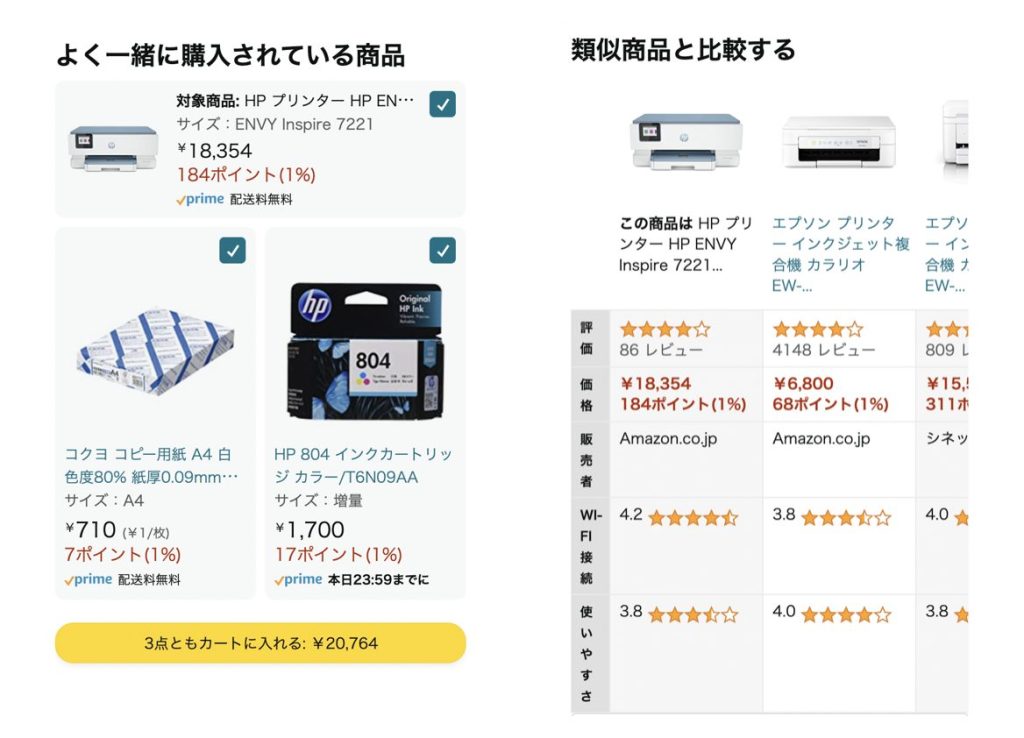
Amazonにも様々なレコメンドが使用されていますが「よく一緒に購入されている商品」はGMVリフトアップ施策として有効です。例えばプリンターの商品ページにインク、コピー用紙を一緒に買いませんかと推薦されます。仕組みとしてはその名の通り一緒に購入されたというデータを元に推薦されています。また、「類似商品と比較する」もプリンターを購入検討しているユーザーにとって非常に有効な機能です。おそらく同一セッション、同一クエリで閲覧されやすいというデータを元にレコメンドしていると思われます。
余談ですが以前携わっていたサービスで「おすすめ」とだけUIに記載したレコメンドを実装したこがあるのですが、ユーザーから「なんでこの商品がおすすめなのか?」「おすすめされるロジックが知りたい」などの問い合わせがたくさん届いたことがあります。きちんと推薦理由を示していなかったからですね。反面教師としていただければと思います。
推薦アルゴリズム
推薦アルゴリズムは「コンテンツベースフィルタリング」と「協調フィルタリング」の2つに分類できます。協調フィルタリングは「メモリベース法」と「モデルベース法」にさらに分割されますが本記事では触れません。
コンテンツベースフィルタリングは商品名、メーカー、カテゴリ、価格、などそのアイテムの内容を示す情報を利用したレコメンドです。ユーザーがどういったアイテムを好むかという情報を元にして、似ているアイテムを計算して推薦します。例えば、ユーザーAはPanasonicが好きという情報と、商品aはPanasonic製であるという情報を元に、ユーザーAに商品aを「Panasonicの新商品」などのレコメンドで掲載します。
サービスを利用しはじめたばかりのユーザーでも自ら興味ジャンルを入力してもらうことで、すぐにレコメンドできるのがコンテンツベースフィルタリングの特徴です。新商品の場合もアイテム情報が入力されていればユーザーに推薦することができます。
協調フィルタリングはサービス内の他のユーザーの過去の行動などから得られる好みの傾向を利用することで推薦します。たとえばユーザーAさんと購買傾向が似ているユーザーBをサービス内から探し出します。そしてユーザーBが購入した他のアイテムをユーザーAさんにも推薦するといった流れです。
また、ユーザーの好みの類似ではなく、類似アイテムをベースにレコメンドすることも可能です。先程のプリンターの「よく一緒に購入されている商品」の例だと、プリンターAと一緒に買われているアイテムであるインクやコピー用紙をサービス内から探し出し提示します。購入データではなく閲覧データを元に計算すると「類似商品と比較する」というようにプリンターAと一緒に閲覧されているプリンターBやプリンターCを探し出して推薦することができます。(もちろん、プリンター以外を一緒に閲覧することもあるので、実装上は商品カテゴリ=プリンターのみ、などの制御をいれて同じ商品カテゴリだけが表示されるような考慮が必要です)
コンテンツベースフィルタリングと比較して多くのデータ、最新のデータをもとに予測精度を高くレコメンドできるのが協調フィルタリングの特徴ですが、サービスを利用しはじめたユーザーや新商品など行動データが少ない場合はうまく推薦できなかったり、ユーザー数が少ないサービスだとそもそもうまく推薦できないなどの特徴があります。
代表的な問題と解決方法
最後に推薦システムを開発・実装するうえで起こりがちな問題と解決方法をまとめます。
| 代表的な問題 | 説明 | 解決方法 |
|---|---|---|
| ユーザー数が少ないサービスでの推薦 | 新規サービスなどユーザー数が少ないと似ているユーザーを探したり、関連アイテムを特定できない | コンテンツベースフィルタリングを用いる |
| コールドスタート問題 | 新規ユーザーや新商品など行動履歴や嗜好情報がない場合に良い推薦ができない | コンテンツベースフィルタリングを用いる(例:会員登録時に興味ジャンルをユーザーに入力してもらう) |
| ハリーポッター問題 | とある時期に多くの人が購入した商品がある場合、他の関係ない商品のページにも「この商品を買った人はハリーポッターを買っています」などの推薦がされてしまう | 人気アイテムの影響を取り除く |
さいごに
今回は推薦システムを学びなおしたので備忘録を兼ねて概要的な部分をまとめました。自分は4年ほど前にはじめてレコメンド機能の導入・構築を検討したのですが、ネットや本で探しても良い文献が見つからなくて本当に困りました。今回、様々な本や記事を読みましたが、入門として概要がまとまっている記事もあまりなかったので、誰かの役に立てると嬉しいです。
▼独学でPythonや機械学習を学びたい人には以下もおすすめです^^
・現役エンジニアが厳選!Pythonのおすすめ本・参考書
・機械学習・ディープラーニングのおすすめ本11冊+α!(初心者〜中級者向け)
Twitterやってます!フォローお願いします
普段はプロダクトマネジメントについて発信しています!